LLM(大規模言語モデル)の歴史

LLMを取り巻く歴史は古く、言語モデルの始まりは1950年頃といわれています。当時は、人間が設定したルールに基づいてコンピューターが言語を解析する「ルールベース」と呼ばれる自然言語処理が行われていました。
1980年代には、文脈や単語の順序から言語処理のパターンを学習する統計的手法が導入され、2000年代初めには主な手法として活用されるようになります。
その後、インターネットの普及とともにニューラルネットワーク(人間の脳の神経回路を模した機械学習モデル)に基づいた言語モデルが開発・発展していき、2017年に発表された「Transformer(トランスフォーマー)」という技術が言語処理性能に革新をもたらしたことで、多くのLLMの開発につながりました。
Transformerは、系列変換タスクのために開発された技術で、ChatGPTなどの対話型AIのベースとなっています。系列変換タスクとは、例えば「入力された日本語の文章を英語の文章に変換する」のように、入力された系列を別の系列に変換して出力することです。
Transformerは主にエンコーダとデコーダという要素で構成されており、エンコーダが入力された情報の解析と特徴の抽出、デコーダがエンコーダからの情報を受け取って別系列に変換するという仕組みです。
LLM(大規模言語モデル)の仕組み

LLMは、下記のような仕組みでテキストを生成しています。
- トークン化
- ベクトル化
- ニューラルネットワークによる学習
- 文脈理解
- デコード
それぞれをわかりやすく解説します。
1.トークン化
トークン化とは、テキストデータを単語や句読点などの最小単位(ト-クン)に分割することです。
OpenAI社は、どのようにトークン化されているか可視化できる「Tokenizer(トークナイザー)」というツールを公開しています。
トークン化の例として、Tokenizerを使ってトークン化した文章を以下に記します。
- Hello World → [”Hello”, ”World”]
- こんにちは、世界 → [”こんにちは”, ”、”, ”世界”]
- LLM(大規模言語モデル) → [”LL”, ”M”, ”(”, ”大”, ”規”, ”模”, ”言”, 語”, ”モデル”, ”)”]
※「GPT-4o および GPT-4o mini」を使用
コンピューターはテキストデータを理解できません。コンピューターに理解してもらうには数値データへの変換が必要なため、変換処理の前段階としてトークン化が行われます。
2.ベクトル化
ベクトル化とは、コンピューターが理解できるように、トークン化したデータを数値に変換する処理のことです。
Tokenizerを使って前述の例文を数値化してみると、次のようになります
- Hello World → [13225, 5922]
- こんにちは、世界 → [95839, 1395, 28428]
- LLM(大規模言語モデル) → [7454, 44, 3603, 1640, 73407, 22801, 17765, 40909, 187451, 3495]
※「GPT-4o および GPT-4o mini」を使用
3.ニューラルネットワークによる学習
ベクトル化の次は、ニューラルネットワークによる学習を行なっていきます。ニューラルネットワークとは、人間の脳内にある神経細胞(ニューロン)と神経回路を人工ニューロンという数式で模した機械学習モデルのことです。
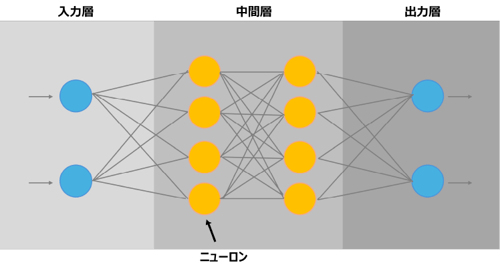
上図のように、ニューラルネットワークは入力層、中間層(隠れ層)、出力層から構成されており、入力層でデータが入力され、中間層でデータの分析が行われたあと、出力層から最終的な情報が出力されます。回路をつなぐオレンジと青の丸がニューロンです。
ニューラルネットワークは、データの入出力を繰り返し反復学習を行うことで、出力結果が最適化されていきます。
4.文脈理解
文脈理解とは、LLMが文章の意味や関係性を理解し、文脈に基づいて適切な答えを出すために重要な機能のことです。
文脈理解のステップでは、共参照解析と依存関係解析という2つの高度な技術が使われています。
共参照解析は、文中の代名詞や指示詞が指すものを特定する技術のことで、例えば、「これを彼女にプレゼントする」の場合、「これ」と「彼女」が指すものを理解します。
依存関係解析は、文中の単語間の依存関係を分析する技術を指し、主語と述語、修飾語と被修飾語などを結びつけることが可能です。例えば、「大きな月が空に浮かんでいる」という言葉の場合、「大きな」と「月」、「空に」と「浮かんでいる」がそれぞれ修飾語、被修飾語として認識されます。
共参照解析と依存関係解析によってLLMは文脈理解が可能となり、より人間らしい受け答えにつながります。
5.デコード
出力データとしてテキストを生成する際には、「デコード」と呼ばれる処理が行われます。デコードとは、ベクトル化していたデータを人間が理解できるテキストデータに変換する処理のことです。
LLMはニューラルネットワークによる学習や文脈理解というステップを踏むため、デコードで人間と対話をしているような自然なコミュニケーションを実現できます。
LLM(大規模言語モデル)の主なサービス

LLMのサービスのなかには、テキスト入力だけでなく、画像や音声、動画などのデータからテキスト出力できるマルチモーダル対応のものもあります。
LLMの主なサービスを下表にまとめました。(※2025年5月時点)
| サービス名 |
開発組織 |
| GPT |
OpenAI |
| BERT(バート) |
Google |
| Gemini(ジェミニ) |
Google |
| PaLM(パルム) |
Google |
| Gemma(ジェマ) |
Google |
| MT-NLG |
Microsoft・NVIDIA(エヌビディア) |
| Claude(クロード) |
Anthropic |
| AmazonNova |
Amazon |
| Llama(ラマ) |
Meta |
| Japanese StableLM Instruct Alpha 7B |
Stability AI Japan |
| Swallow |
東京工業大学の研究チーム・
国立研究開発法人 産業技術総合研究所 |
| LHTM(ラートム) |
株式会社オルツ |
| tsuzumi |
日本電信電話株式会社(NTT) |
| プライベートLLM(「仕事のAI」サービスの一部) |
株式会社リコー |
| cotomi |
日本電気株式会社(NEC) |
| Stockmark LLM |
ストックマーク株式会社 |
| PLaMo(プラモ) |
株式会社Preferred Elements |
| LLM-jp |
LLM-jp |
| CyberAgentLM3 |
株式会社サイバーエージェント |
LLMはサービスによってパラメータ数が異なり、総務省の資料によると、米国企業が開発したLLMのパラメータ数が群を抜いて多いことがわかります。
 参考:令和6年版情報通信白書(総務省)
参考:令和6年版情報通信白書(総務省)
なお、総務省は、日本語に強いLLMの利活用のためには構築過程や活用するデータが明らかで透明性の高い、国産のLLM構築が必要としています。
2025年現在、さまざまな日本の企業・組織がLLM開発に取り組んでいる状況を見ると、今後国内においてさらに高精度のLLMが開発される可能性があります。
LLM(大規模言語モデル)の活用事例

LLMは、次のようなシーンで活用できます。
- テキストの生成・校正
- カスタマーサポート
- 情報分析
- プログラミング
どのように活用できるのかを解説します。
1.テキストの生成・校正
言語を扱うLLMは、テキストの生成や校正、要約、翻訳に活用できます。例えば、レポートやメール文面を作成したり、文章に誤字脱字や文法誤りがないかを確認できたり、要点を押さえて長文をまとめられたりします。
動画や音声ファイルも取り扱える場合、議事録の作成も可能でしょう。また、翻訳に用いれば、従来の翻訳サービスよりも文脈を汲み取った自然な翻訳テキストの出力につながります。
LLMでテキストの生成などを行えば、業務の効率化によって生産性が向上する可能性があります。ビジネスにおいて文章を書いたり読んだりする機会は多いため、LLMを活用すると大幅な時間短縮につながるでしょう。
2.カスタマーサポート
LLMは、高度な学習によって複雑な質問にも答えられるようになっているため、カスタマーサポートとして活用できます。
顧客の質問に対しスムーズな回答ができるLLMに24時間365日、顧客対応をしてもらえば、顧客満足度を上げられたり従業員の負担やコスト削減を実現できたりするでしょう。
カスタマーサポートのリソースが足りない、顧客からの問い合わせに迅速に対応したいという企業は、LLMを活用した自動応答プログラムである「AIチャットボット」を導入すると効果的かもしれません。
3.情報分析
膨大なデータを学習しているLLMは、情報分析にも活かせるでしょう。
例えば医療分野においては、患者の履歴を分析し、適切な医療や治療計画を提案してくれます。金融分野では、市場傾向と財務レポートの分析によって、リスク評価が可能です。LLMに最新の市場動向を分析してもらえば、マーケティング戦略も立てやすくなるでしょう。
高度な分析による、パーソナライズされた提案や客観的な評価は、顧客の自社に対する満足感や信頼感を高めたり、企業の効果的な戦略展開につながったりするでしょう。
4.プログラミング
LLMは、プログラミングにおけるコーディングやエラーチェックなども行えます。プロジェクト開発に必要なコードの生成やデバッグに活用するなど、プログラミングのサポート的役割を担ってくれるため、エンジニアの業務効率化を図れるでしょう。
また、プログラミングスキルがなくても的確なプロンプトによって容易にコード生成ができる機能は、懸念されているIT人材不足を補える可能性があります。
LLM(大規模言語モデル)の注意点

文章作成、プログラミングのサポート、顧客対応など、さまざまなシーンで活用できるLLMですが、以下のような注意点もあります。
- 誤った情報が出力される恐れがある
- 攻撃手段になり得る
- 情報漏洩や法的リスクがある
LLMの活用によってトラブルが生じないように、注意点を把握しておきましょう。
1.誤った情報が出力される恐れがある
LLMは、「ハルシネーション」と呼ばれる現象が起こる恐れがあります。ハルシネーションとは日本語で「幻覚」を意味し、AIが知らないことを聞かれた際に「さも正解であるかのように」嘘をつくことです。
例えば、下記がハルシネーションとして挙げられます。
| プロンプト(指示) |
AIの回答 |
ハルシネーションの発生原因予測 |
| 織田信長を討ち取ったのは誰ですか? |
豊臣秀吉です。 |
学習データの誤情報 |
| 1000年前のパソコンの機能を教えてください |
1000年前にパソコンは存在しないのに、架空のパソコンの機能を実在していたかのように回答 |
システムの生成プロセスの問題(AIが自分の回答内容について正確性を評価できていない) |
ハルシネーションは、LLMの学習データに誤情報や曖昧な情報があったり、AIが学習データを誤って認識したりすることが原因で発生します。LLMを活用する人間のプロンプトが不明確な場合も、ハルシネーションを引き起こしやすいです。
システムの進化に伴ってハルシネーションは減っていくと予測されますが、必ずしも正しい情報を出力するとは限らないため、適切な意思決定をしたり情報を正しく使ったりできるように、ハルシネーションが起こる可能性を考慮した活用が求められます。
2.攻撃手段になり得る
LLMは、悪意のある人物が使うと攻撃手段になり得ます。
「プロンプトインジェクション」と呼ばれる攻撃手法で、AIに誤作動を起こさせるプロンプトを入力し、本来出力されるべきでない情報を出力させたり制御不能にしたりして、機密情報の漏洩や不正操作などを行います。
プロンプトインジェクションを防ぐには、入力できる内容に制限を設ける、入力される前にフィルタリングをする、システムに与える権限を最小限にするなどのセキュリティ対策が重要です。
ユーザーにプロンプトインジェクションのリスクを啓蒙し、出力された情報が不適切なものや機密情報などの場合は報告してもらえるように促すことも、対策として効果的でしょう。
3.情報漏洩や法的リスクがある
LLMに個人情報や機密情報を入力すると、学習に使われて他ユーザーへの回答で出力される恐れがあります。情報漏洩を防ぐには、漏洩しては困る情報を入力しない、入力内容を学習しないように設定するなどの対策が必要です。
また、LLMは著作権で保護された内容を出力するケースもあるため、著作権を侵害する法的リスクもあります。AIのバイアスによって、例えば「日本人は根暗だ」のように、特定の属性に対する不適切な表現などが出力されると、倫理的な問題も生じかねません。
LLMを問題なく活用するには、出力された内容に法的・倫理的リスクがないかをチェックすることが大切です。
まとめ

LLMは、カスタマーサポートやプログラミングなどに活用でき、業務効率化や生産性の向上につながります。
一方で、LLMにはハルシネーションや情報漏洩、著作権侵害などの課題もあるため、LLMの便利さを活かしつつも、発生しうるリスクに備え、適切な対策を講じていくことが重要です。


